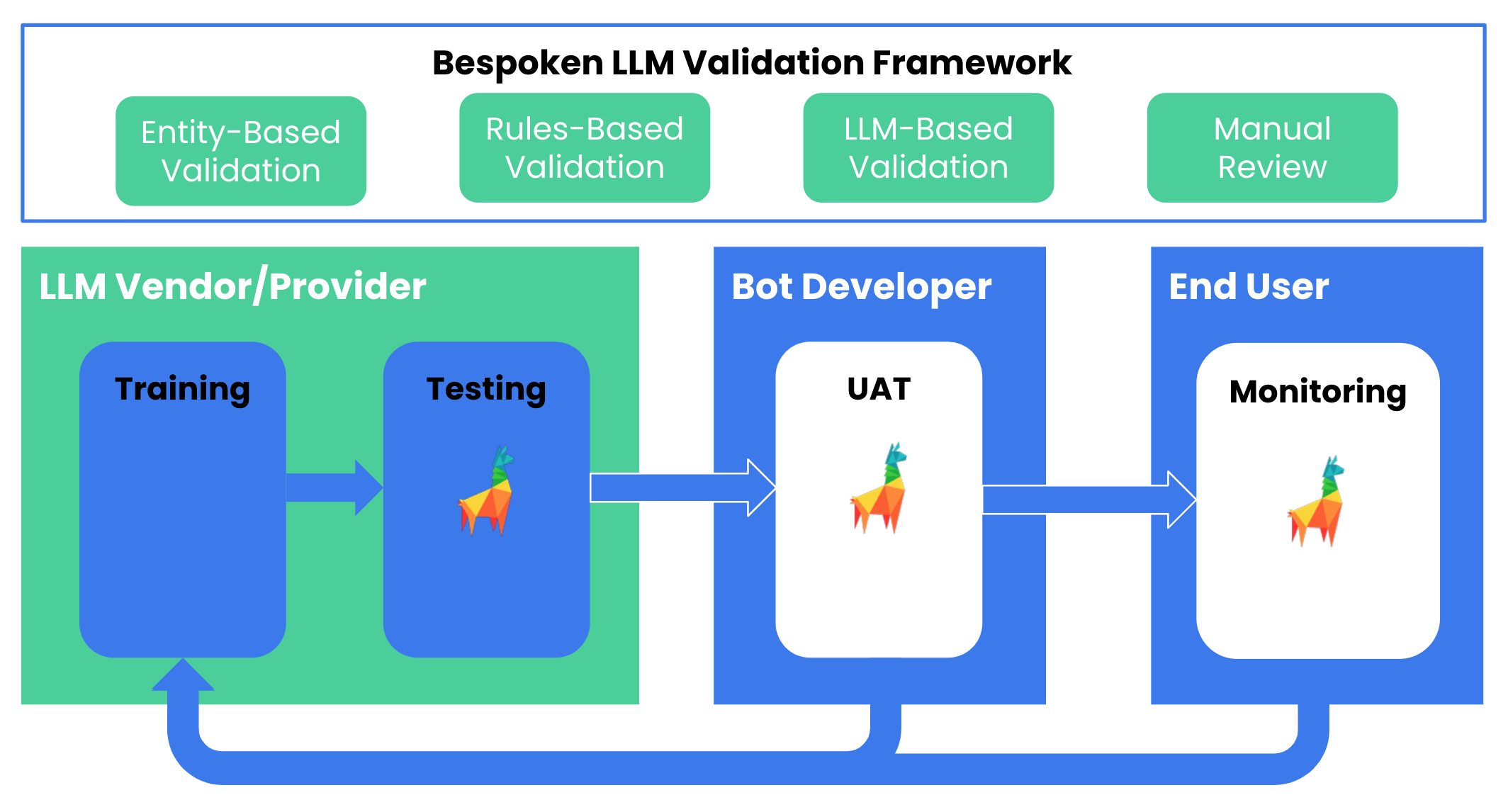
Highlights of our report:
- ChatGPT outperformed outperformed Google and Alexa on answering general knowledge question.
- All the agents struggled with declining to answer questions when there is no answer (i.e., nonsensical and/or trick questions)
- This is just the start - we plan to expand these benchmarks for other platforms - email us (contact@bespoken.io) with ideas or for customized testing on your own in-house bot/LLM
Read on below for the details!