Benchmark Objective
Our goal in running this benchmark was to provide accurate, reliable data on how well various voice platforms perform.
This first test evaluates the three biggest voice assistant platforms on how they do on complex, general knowledge questions
Our goal is to provide interesting insight into how the platforms work, as well as show off our technology and processes at Bespoken.
To that end, we combine:
- Our core testing and tuning technology
- Github for hosting and managing the test scripts
- Github Actions for executing the benchmark
- MySQL and Metabase for reporting
All of this is public and open-source - part of our effort to "test in public". We want to show off not just our results, but also how we do our testing. We believe both are critical to successful automation.
Benchmark Dataset
We leveraged the excellent ComQA dataset for this, specifically their Dev question dataset. From their website:
ComQA is a dataset of 11,214 questions, which were collected from WikiAnswers, a community question answering website. By collecting questions from such a site we ensure that the information needs are ones of interest to actual users. Moreover, questions posed there are often cannot be answered by commercial search engines or QA technology, making them more interesting for driving future research compared to those collected from an engine's query log. The dataset contains questions with various challenging phenomena such as the need for temporal reasoning, comparison (e.g., comparatives, superlatives, ordinals), compositionality (multiple, possibly nested, subquestions with multiple entities), and unanswerable questions (e.g., Who was the first human being on Mars?).
In their paper, they elaborate further on each of these question categories. For example:
A question is compositional if answering it requires answering more primitive questions and combining these. These can be intersection or nested questions. Intersection questions are ones where two or more sub-questions can be answered independently, and their answers intersected (e.g., “Which films featuring Tom Hanks did Spielberg direct?”). In nested questions, the answer to one subquestion is necessary to answer another ("Who were the parents of the thirteenth president of the US?").
There are tough questions, by design. Their phrasing can be confusing, the subject matter bordering on obscure, and the grammar can be downright antisocial. For all these reasons, it makes them a very good measuring stick for the performance of virtual assistants, the bots meant to handle our often clumsy inquiries gracefully and efficiently.
Take a look at the detailed results here to see how we classified different questions.
Benchmark Test Execution
This dataset comprises 937 questions, which we run against the following three platforms:
- Amazon Echo Show 5
- Apple iPad Mini
- Google Nest Home Hub
We used our Bespoken Test Robots to "talk" with these devices and record their audio and visual responses. With our Test Robots we are able to execute these tests in a completely automated manner.
For example, our Test Robot says: "Hey Google, when did Bear Bryant coach Kentucky?"
The audio response from Google is: "sure here's some helpful information I found on the web"
The visual response from Google is:
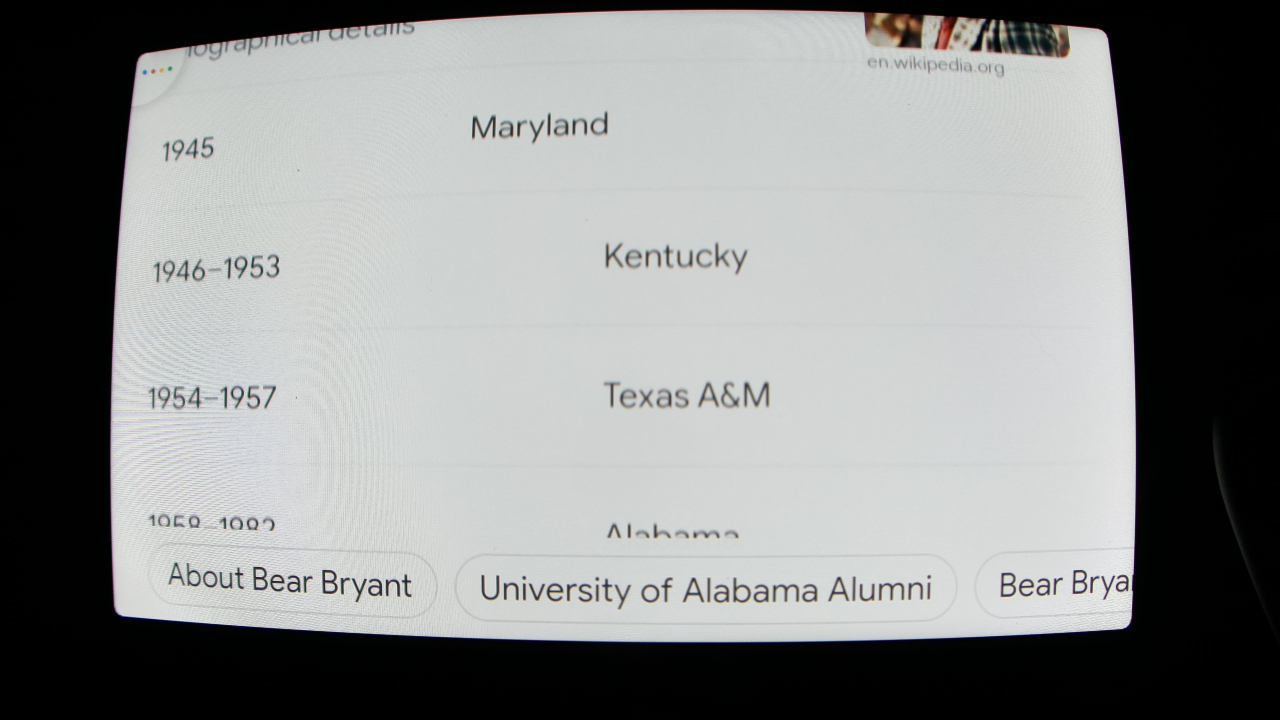
Our OCR sees that the display shows 1946-1953 Kentucky, which is the correct answer, so this test is marked as success!
We performed this for every question in our dataset, across each of the devices listed above.
Benchmark Results
The complete results are viewable here - you can see what happened with each utterance in detail, as well as how the question was annotated.
You can also view what happened as part of the specific runs inside of Github. For example, here is the run for the Nest Home Hub:
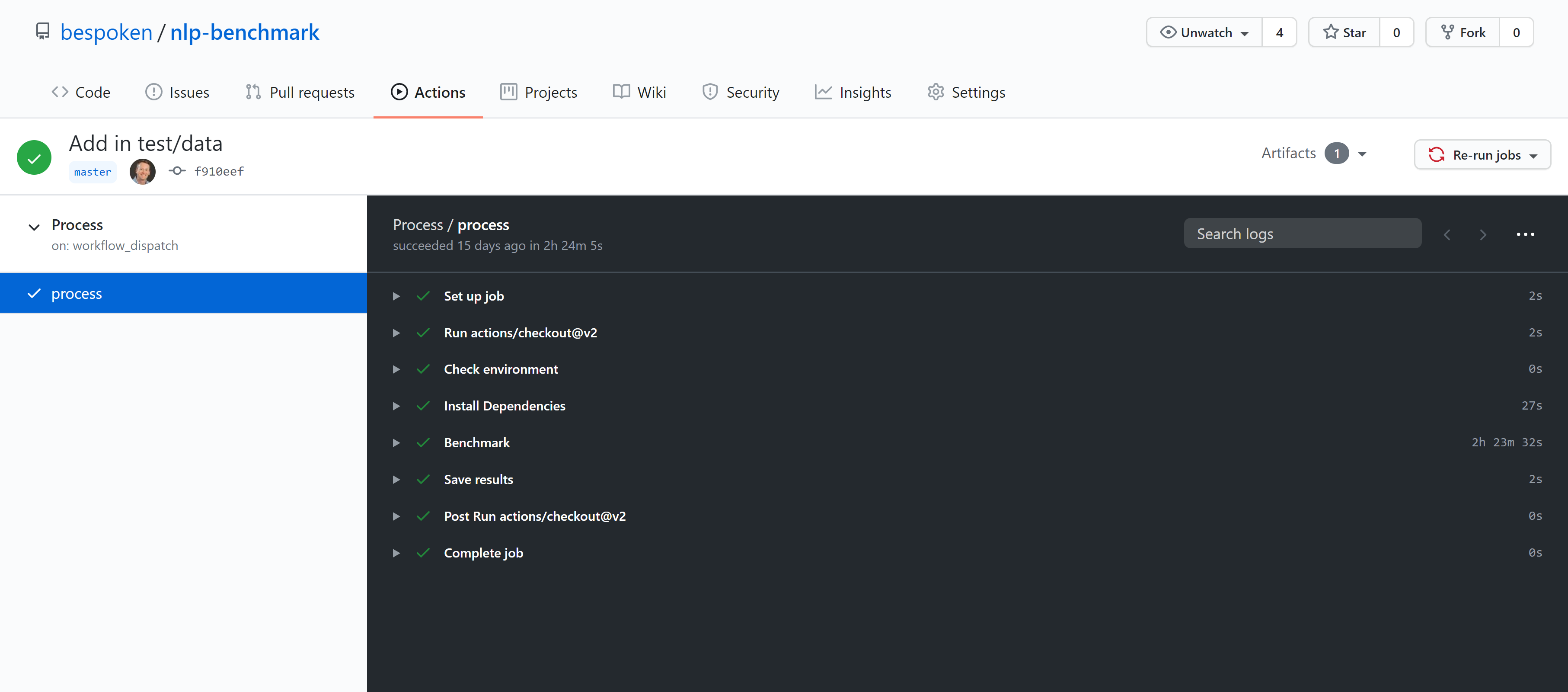
As you can see, Github is not just a great environment for maintaining our code, but also for actually executing our tests. We commonly use this with customers. It allows for easy collaboration, operations and reporting.
We can assist with your specialized testing and tuning needs at Bespoken - just reach out to contact@bespoken.io and we can show you how to not just measure, but measurably improve, the performance of your voice experience.