Benchmark Objective
Our goal in running this benchmark was to provide accurate, reliable data on how well various voice platforms perform.
Our goal in running this benchmark was to provide accurate, reliable data on how well various voice platforms perform.
This test evaluates three relatively new, conversationally-focused Digital Contact Center platforms on their Speech Recognition Accuracy.
We believe that these findings provide relevant, meaningful insights into how the platforms work, as well as show off the capabilities and processes of Bespoken and DefinedCrowd.
The Process
To that end, the process for our benchmark is illustrated below:
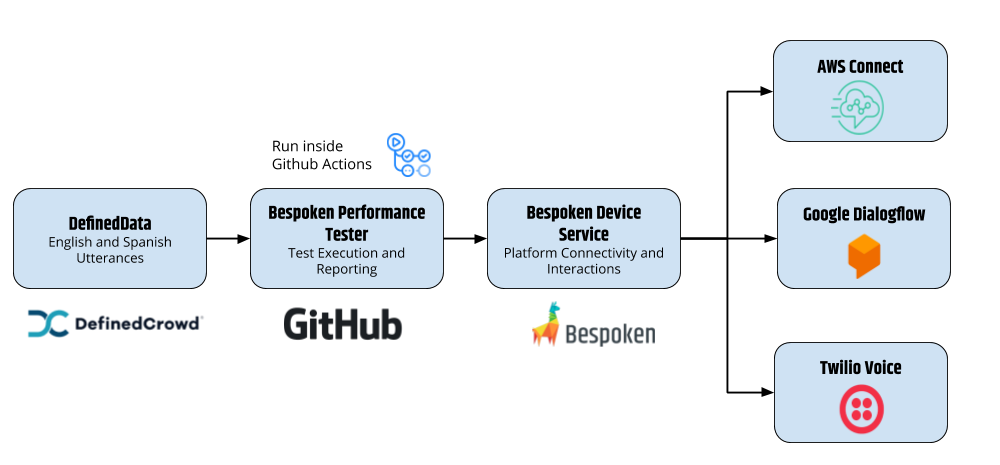
The flow works as follows:
- DefinedData audio utterances in English and Spanish are loaded from S3 by Bespoken along with their transcripts
- The Bespoken Performance Tester calls the platform being tested and "speaks" the utterance, in exactly the way a user would. This is true end-to-end testing, done at scale.
- Each platform being tested provides us with their own call transcript, this is compared to the transcript we have from step 1.
- The Word Error Rate and other analytics are calculated and stored in MySQL for reporting.
Tests are run with Github, as part of our Bespoken Benchmark project.
All of this is public and open-source - part of our effort to "test in public". We want to show off not just our results, but also how we do our testing. We believe both are critical to successful automation.
The Data
We performed this benchmark with our partner DefinedCrowd using samples from their DefinedData offering.
Some highlights from these datasets:
- They include two different languages
- They represent three different domains: banking, insurance and retail
- They are a small subset of DefinedData's overall dataset, which includes more than X,000 utterances
- They are off-the-shelf and fully annotated, making it easy for brands to leverage
The Results
These results are not an academic exercise - they can guide your decision-making if you are selecting a platform for your own contact center.
What's more, measuring is just the first step: tuning and training are the keys to creating great voice experiences. By first conducting these tests, we can then provide highly specific guidance on how to refine your model and optimize your call deflection, call center spend, and customer satisfaction.
In recent work with a major utilities company, we were able to:
- Rapidly identify critical functional and AI model issues
- Reduce manual testing time by more than 90%
- Reduce errors by more than 50%
- Increase throughout by more than 200%
To get assistance with your specialized testing and tuning needs from DefinedCrowd and Bespoken, just reach out to benchmark@bespoken.io. Our team can show you how to not just measure, but measurably improve, the performance of your voice experiences.